
簡易的に書き込みをしたい場合DBサーバーを立てるよりもSpreadSheetに書きこんだ方が楽な気がするのでメモ
Spread SheetをAPIで操作する方法かこちらに記載
Spread Sheetのマニフェスト
書き込み可能セル数:
1000万セル (2026/04/15時点: ソース)
10個のカラムであれば1000万/10 = 100万件レコードの挿入可能
個人の開発であれば十分過ぎる。
Sheet API Rate Limit:
1ユーザ1プロジェクトあたり60req/min (2022/06/12時点: ソース)
ReadとWriteで別カウント
1回のリクエストに対してなので、バッチで投げても1リクエスト扱い
Masterテーブルして運用するには60rpmは心もとない。
参照機会が少ないシステムであれば本番環境で運用も可能かもしれない。
Spread Sheetを用いた運用例
Instagramのユーザの、投稿数、フォロワー数を日時で抽出し、Spread Sheetに書き込む
参照方法としては、Spread Sheetを直接参照か、Google Data PortalやTableauのようなBIツールを想定
適当にSpread Sheetを用意する
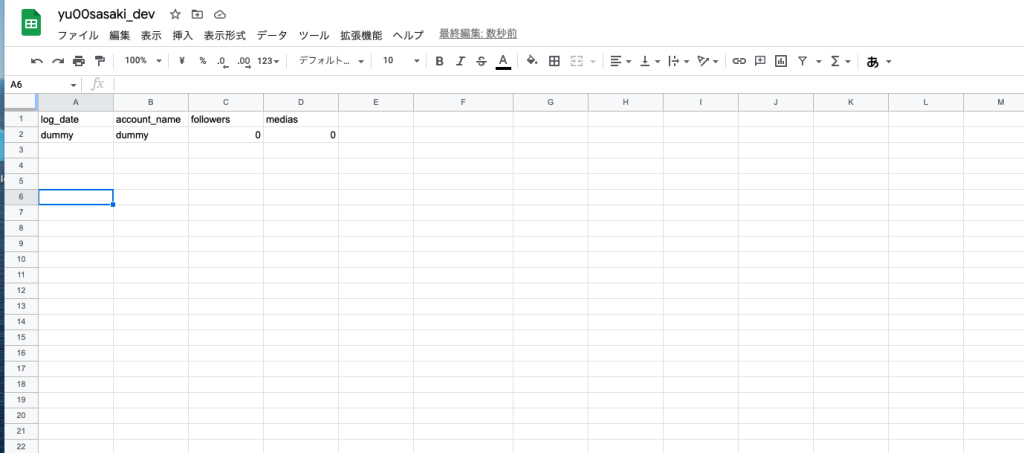
定義は以下のようにした
| log_date | account_name | followers | medias |
| 取得日 | アカウント名 | フォロワー数 | 投稿数 |
Instagram Graph APIで特定アカウントの情報を取得
BASE_URL = "https://graph.facebook.com/v12.0/{USER_ID}?fields=business_discovery.username({SEARCH_ID}){FIELDS}&access_token={ACCESS_TOKEN}"
#fieldsには特殊文字が入る可能性があるので変数で分離
fields = "{id,followers_count,media_count}"
#user_id=認証ユーザのID
#search_id=抽出したいアカウントID
#acccess_token=サードトークン
req_url = BASE_URL.format(USER_ID=user_id, SEARCH_ID=search_id, FIELDS=fields, ACCESS_TOKEN=access_token)
response = requests.get(req_url)
insta_data = json.loads(response.text)抽出できるJSONは以下
{
"business_discovery": {
"id": "<抽出したアカウントのIGID>",
"followers_count": <フォロワー数>,
"media_count": <投稿数>
},
"id": "<自身のID>"
}これをspread sheetにアップロードする
gc = gspread.service_account(filename=file_name)
#spread sheetを選択。sheet_idはspread sheetの第三階層
#https://docs.google.com/spreadsheets/d/の後の部分)
#例:https://docs.google.com/spreadsheets/d/hogehogehoge/edit?hl=JA#gid=0
#↑hogehogehogeがsheet_id
sh = gc.open_by_key(sheet_id)
#シートを選択。sheet_nameはシートタブ名
worksheet = sh.worksheet(sheet_name)
#シートのデータをDataframe方式で出力
sheet_df = pd.DataFrame(worksheet.get_all_records(head=1))
#追記する
info_dict = {}
info_dict["log_date"] = datetime.date.today().strftime('%Y%m%d')
info_dict["account_name"] = user_id
info_dict["followers"] = insta_data["business_discovery"]["followers_count"]
info_dict["medias"] = insta_data["business_discovery"]["media_count"]
sheet_df = sheet_df.append(
{
"log_date": info_dict["log_date"],
"account_name": info_dict["account_name"],
"followers": info_dict["followers"],
"medias": info_dict["medias"]
}, ignore_index=True
)
#バッチでアップデートするために行列情報を抽出する
row = len(sheet_df) + 1
col = len(sheet_df.columns.values.tolist())
range_str = "A1:P{row_num}".format(row_num=row)
worksheet.batch_update(
[{'range': range_str, 'values': [sheet_df.columns.values.tolist()] + sheet_df.values.tolist()}]
)spread sheetを確認
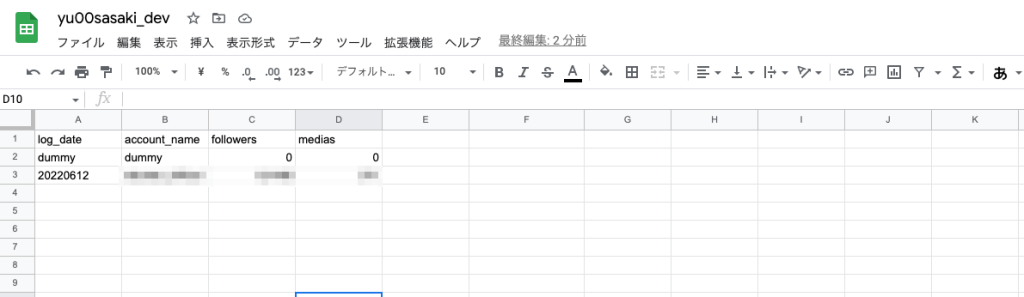
追記できた。
実際DMとして使う場合は、dataframeでフィルターしてバッチで上書きするとよい。
例えば同日にDBを更新したい場合はlog_date=同日で絞り込むなど。
BIツールとの繋ぎ込みは別記事で紹介予定

コメント