
Instagram Graph APIを用いてハッシュタグから、画像や情報を抽出する方法をメモ
流れとしては、
①ハッシュタグからハッシュIDを抽出
②ハッシュIDから投稿情報を抽出
③投稿情報から画像を抽出
の3段階で実施。①と②についてはGraph APIを活用
①ハッシュタグからハッシュIDを抽出
/ig_hashtag_searchを用いて、ハッシュタグからハッシュIDを抽出
トークンの詳細は以下

USER_ID = 認証したuserのid
HASH_QUERY = 抽出したいハッシュタグ
ACCESS_TOKEN = サードトークン
https://graph.facebook.com/v9.0/ig_hashtag_search?user_id={USER_ID}&q={HASH_QUERY}&access_token={ACCESS_TOKEN}例: 「winter」というハッシュタグの場合以下のようなレスポンス
{
"data": [
{
"id": "17843863474034241"
}
]
}idがハッシュidに相当のものである
②ハッシュIDから投稿情報を抽出
先ほどのハッシュidを用いて、投稿情報を抽出
HASH_ID = 先ほどのハッシュid
SEARCH_TYPE = ソート方法. top_media:人気順、recent_media:新規順
USER_ID = 認証したuserのid
FIELDS = 抽出したい情報
ACCESS_TOKEN = サードトークン
https://graph.facebook.com/v9.0/{HASH_ID}/{SEARCH_TYPE}?user_id={USER_ID}&fields={FIELDS}&access_token={ACCESS_TOKEN}FIELDはmedia_url,media_type,permalink,caption,like_count,comments_count,timestampを選択、詳細は以下を参照
https://developers.facebook.com/docs/instagram-api/reference/ig-hashtag/recent-media
③投稿情報から画像を抽出
②より以下の情報がJSON形式で取れる
{
"data": [
{
"id": "hoge",
"ig_id": "hoge",
"username": "hoge",
"caption": "hoge",
"comments_count": 0,
"is_comment_enabled": true,
"like_count": 0,
"media_product_type": "FEED",
"media_url": "https://<URL>", ・・・これ
"media_type": "CAROUSEL_ALBUM",
"permalink": "https://www.instagram.com/p/<URL>/",
"owner": {
"id": "hoge"
},
"shortcode": "hoge",
"timestamp": "yyyy-mm-ddThh:mm:ss+0000"
},
],
"paging": {
"cursors": {
"before": "hoge",
"after": "hoge"
},
"next": "hoge"
}
}
media_url内に時限のCDNリンクが載ってあるのでダウンロードをすれば端末に落とすことが可能
pythonでの実装例
with open(file) as fd:
insta_data = json.load(fd)
medias = insta_data["data"]
for media in medias:
#IMAGEデータのみ分析する
if not media["media_type"] == "IMAGE":
continue
#画像のダウンロード
media_url = media["media_url"]
response = requests.get(media_url)
image = response.content
with open(image_dir/f"image{counter}.jpg" , "wb") as imd:
imd.write(image)
counter+=1サンプル
高田馬場で取ってみる
※人物にはマスクをかけています
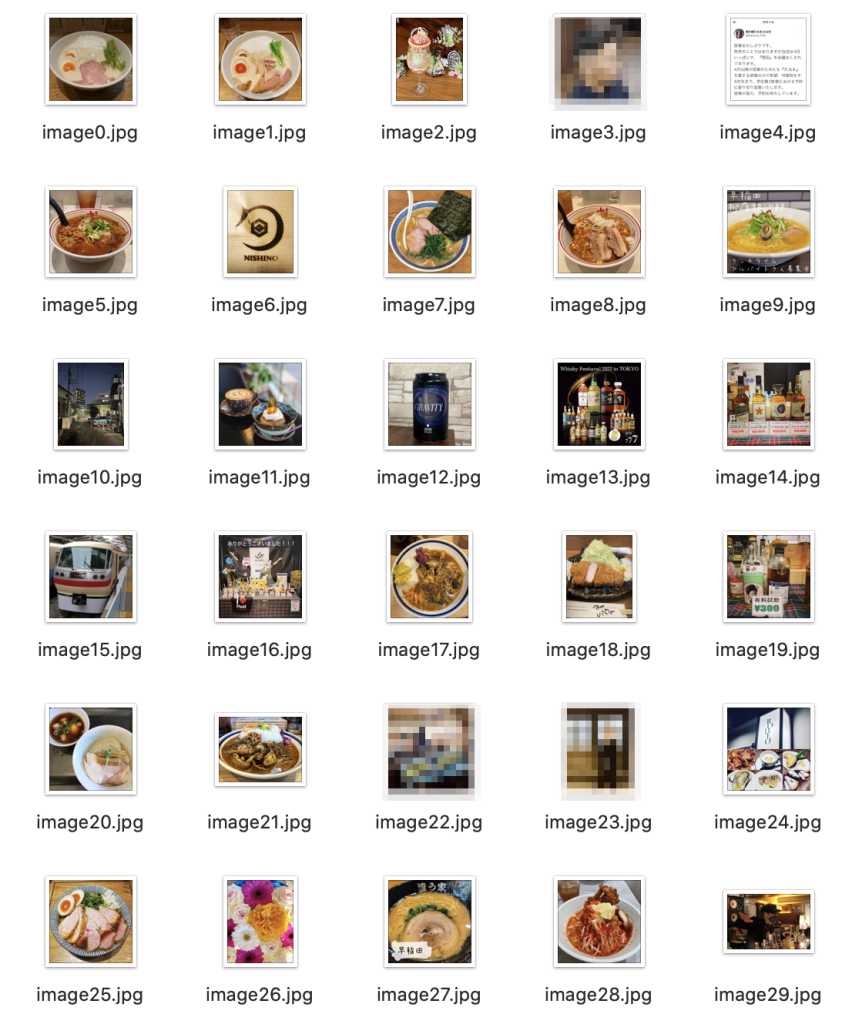
ラーメンが多い


コメント