
Pandas(DataFrame)において、とあるIDの集合Aと集合BのANDやORを見たい時に、取得方法を毎回悩んでしまうので、やり方を整理。NdarrayとSetで扱う方法で整理する。
前処理
タイタニックの乗船データを用いて検証を行う。
import pandas as pd
import numpy as np
# titanicデータを取得する
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(url, encoding='UTF-8')
df_concat.head(100)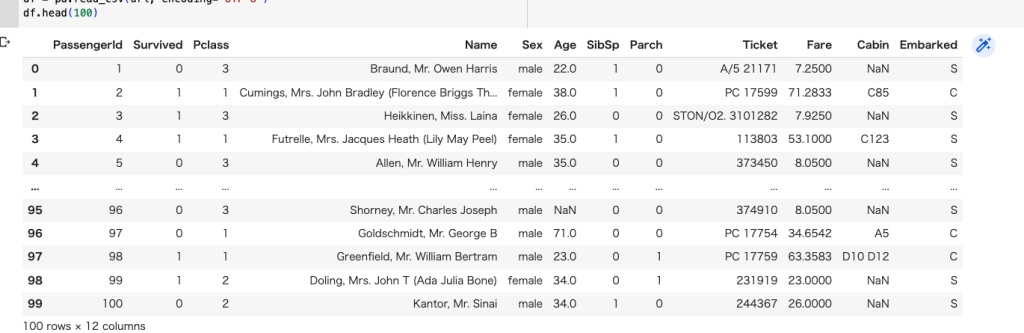
クラスと生存者でIDを取得する。
Numpy関数の利用
Numpyで扱うためにNdArrayクラスとして客室クラスと生存者でIDを取得する。
class_1_id = df.query("Pclass==1").PassengerId.unique()
survived_id = df.query("Survived==1").PassengerId.unique()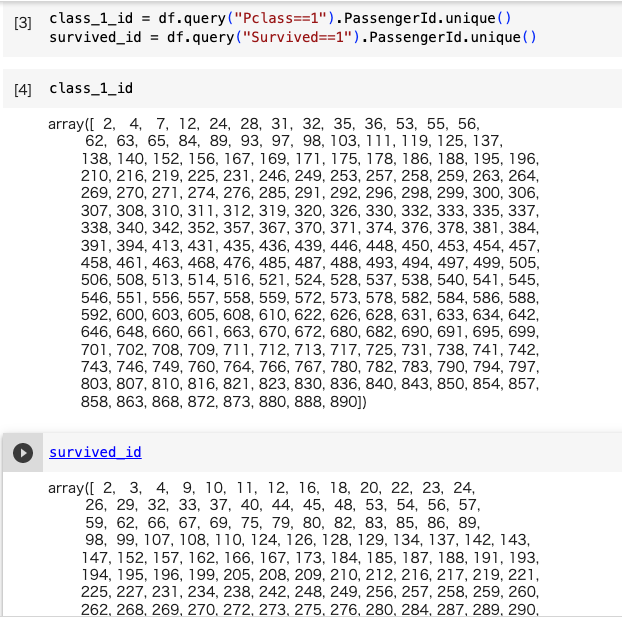
Numpyで積集合(AND)を取る場合、np.intersect1dを用いる。
np.intersect1d(class_1_id, survived_id)和集合(OR)を取る場合、np.union1dを用いる。
np.union1d(class_1_id, survived_id)差集合(Diff)を取る場合、np.setdiff1dを用いる。
np.setdiff1d(class_1_id, survived_id)この場合、class_1_idにだけ含まれるidを抽出できる。
Set関数の利用
Numpyを経由しないで、処理を行う場合、Set関数を用いる。
class_1_id_set = set(df.query("Pclass==1").PassengerId)
survived_id_set = set(df.query("Survived==1").PassengerId)
Setで積集合(AND)を取る場合、Set同士で&を用いる。
class_1_id_set & survived_id_set和集合(OR)を取る場合|を用いる。
class_1_id_set | survived_id_set差集合(Diff)を取る場合、–を用いる。
class_1_id_set - survived_id_setこの場合、class_1_idにだけ含まれるidを抽出できる。
所感
Notebookでdebugをしながら検証する場合、NdArrayの方が、視認性は高い。
Setの方が、直感的に操作が可能。
=>NdArrayの場合、setdiff1dのような関数を覚える必要があるのでやや面倒。


コメント