
Jupyter Notebookで大量データを読み込む場合、見切れてしまう。
初期の分析段階では目視でチェックを行いたい部分も多々あるため、対処方法を整理。
対処方法
pandasの設定値を変更。
デフォルトでは行が60、列(カラム数)が20となっている。
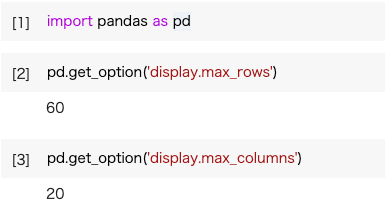
このオプションの値を引き上げれば解決。
#行を変更
pd.set_option('display.max_rows', 100)
#列を変更
pd.set_option('display.max_columns', 100)検証
import pandas as pd
# titanicデータを取得する
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(url, encoding='UTF-8')
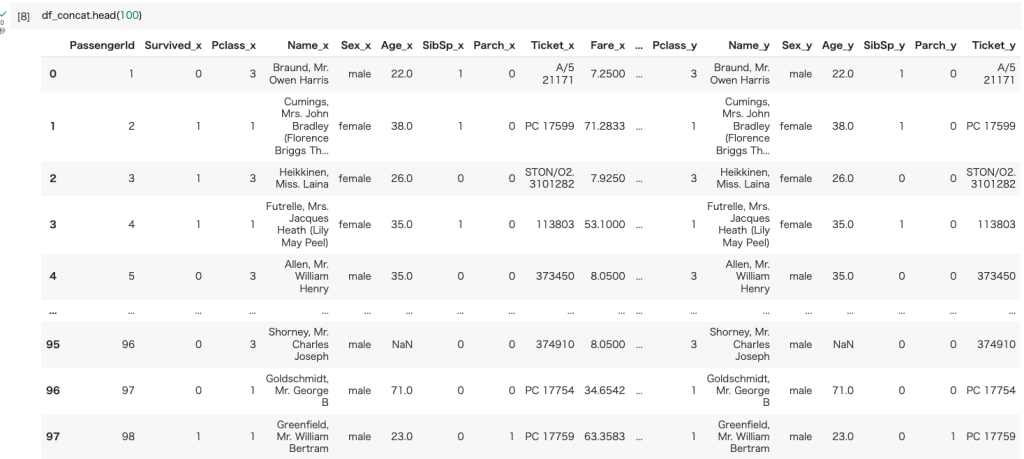
df_concat = pd.merge(df, df, on='PassengerId')
df_concat.head(100)行列共に見切れる。
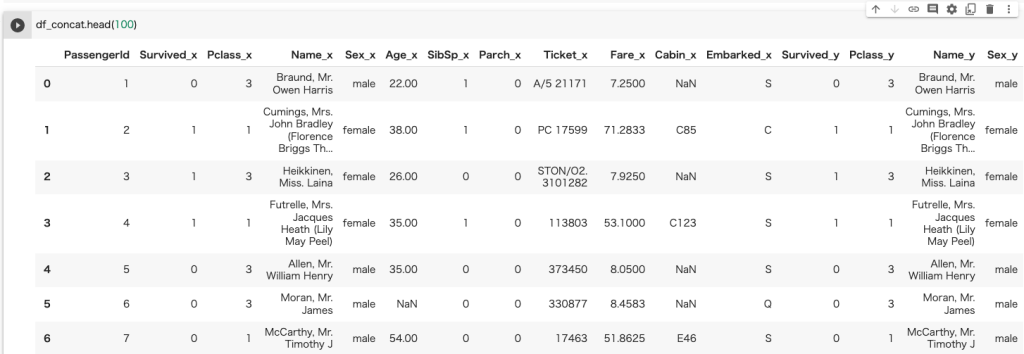
#上限を引き上げ
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', 100)行列共に表示することができた。


コメント